Get HTML source of page in Selenium
Selenium Python - Get HTML source of page
In this tutorial, you will learn how to get the HTML source of a webpage using Selenium in Python.
To get the HTML source of a webpage in Selenium Python, load the URL, and read the page_source attribute of the driver object. The attribute returns the source of the HTML page as a string.
source = driver.page_sourceExample
In this example, we shall consider loading the HTML file at path /tmp/selenium/index-13.html . The contents of this HTML file is given below.
<html>
<body>
<h2>Hello User!</h2>
<div id="parent">
<div id="child1">This is child 1.</div>
<div id="child2">This is child 2.</div>
<div id="child3">This is child 3.</div>
</div>
</body>
</html>In the following program, we initialize a driver, then we load the specific URL, and read the page_source attribute from the driver object. We shall store the returned value in a variable and print it to standard output.
Python Program
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
# Setup chrome driver
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# Navigate to the url
driver.get('/tmp/selenium/index-13.html')
# Get HTML source of webpage
source = driver.page_source
print(source)
# Close the driver
driver.quit()Output
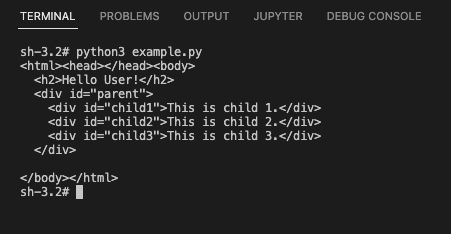
Summary
In this Python Selenium tutorial, we have given instructions on how to get the HTML source of a page, with example program.