Get all paragraph elements using Selenium
Selenium Python - Get all paragraphs
In this tutorial, you will learn how to get all the paragraph elements using Selenium in Python.
To get all the paragraph elements in Selenium Python, call find_elements() method of the element object and pass the arguments: "By.TAGNAME" for by parameter and "p" for the value parameter.
The find_elements() method returns a list of WebElement objects, where each object in the list is a paragraph element.
The following code snippet returns all the paragraphs in the page.
driver.find_elements(By.TAG_NAME, "p")Examples
1. Get all the "p" tag elements in the page
In the following example, we shall consider loading the HTML file at path /tmp/selenium/index-8.html . The contents of this HTML file is given below.
<html>
<body>
<h2>Hello User!</h2>
<p>This is first paragraph.</p>
<p>This is second paragraph.</p>
<p>This is third paragraph.</p>
<h2>Another section</h2>
<p>This is fourth paragraph.</p>
</body>
</html>In the following program, we initialize a webdriver, navigate to a specific URL, get all the paragraph elements, and print them to standard output using a Python For loop statement.
Python Program
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
# Setup chrome driver
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# Navigate to the url
driver.get('/tmp/selenium/index-8.html')
# Get all the paragraph elements
elements = driver.find_elements(By.TAG_NAME, "p")
# Iterate over the paragraph elements
for index, para in enumerate(elements):
print(f'Paragraph {index+1} :\n{para.get_attribute("outerHTML")}\n')
# Close the driver
driver.quit()Output
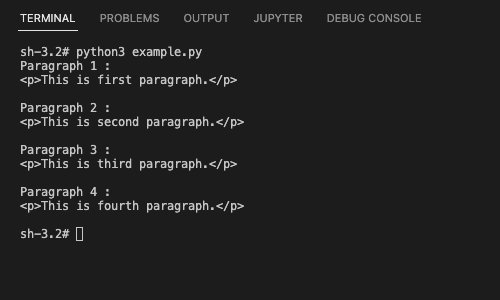
If you want just the paragraph text, use the following code.
Python Program
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
# Setup chrome driver
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# Navigate to the url
driver.get('/tmp/selenium/index-8.html')
# Get all the paragraph elements
elements = driver.find_elements(By.TAG_NAME, "p")
# Iterate over the paragraph elements
for index, para in enumerate(elements):
print(f'Paragraph {index+1} :\n{para.text}\n')
# Close the driver
driver.quit()Output
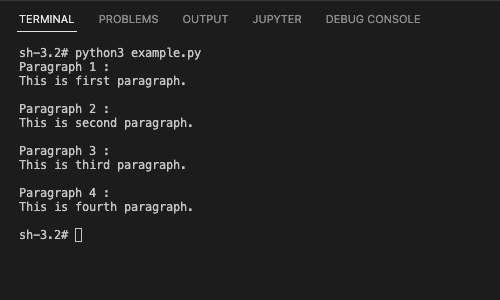
Summary
In this Python Selenium tutorial, we have given instructions on how to get all the paragraph elements in the document using find_elements() method of WebElement class, with example programs.